Recommender Systems
Building a User-Based Collaborative Filtering System
Beer reviews data from beeradvocate. Source citation: J. McAuley and J. Leskovec. From amateurs to connoisseurs: modeling the evolution of user expertise through online reviews. WWW, 2013.
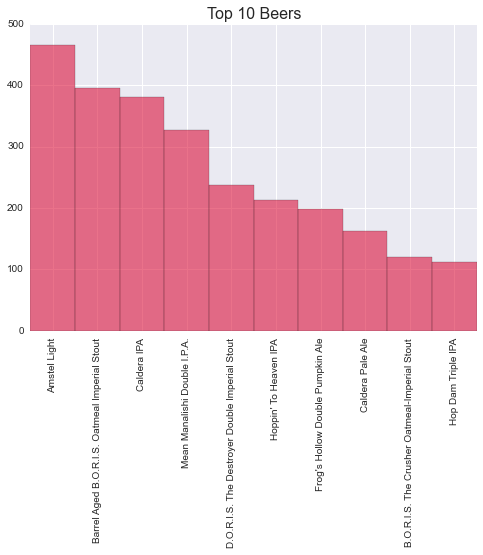
5000 observations are used for this model. First some exploratory data analysis, let's find the top ten most popular beers.
data=list(parse('/users/davidt/documents/cse_190/datasets2/Beeradvocate.txt.gz')) [:5000]
data[0]
{'beer/ABV': '5.00',
'beer/beerId': '47986',
'beer/brewerId': '10325',
'beer/name': 'Sausa Weizen',
'beer/style': 'Hefeweizen',
'review/appearance': '2.5',
'review/aroma': '2',
'review/overall': '1.5',
'review/palate': '1.5',
'review/profileName': 'stcules',
'review/taste': '1.5',
'review/text': 'A lot of foam. But a lot.\tIn the smell some banana, and then lactic and tart. Not a good start.\tQuite dark orange in color, with a lively carbonation (now visible, under the foam).\tAgain tending to lactic sourness.\tSame for the taste. With some yeast and banana.',
'review/time': '1234817823'}
def removeNonAscii(datum):
return "".join(i for i in datum if ord(i)<128)
items = Counter([b['beer/name'] for b in data])
values = [count for item, count in items.most_common()[:10]]
labels = [item for item, count in items.most_common()[:10]]
labels = [removeNonAscii(b) for b in labels]
indexes = numpy.arange(len(labels))
width = 1
plt.bar(indexes, values, width, color='crimson', alpha = 0.6)
plt.xticks(indexes + width * 0.5, labels, rotation=90)
plt.title("Top 10 Beers", fontsize=16)
I will use the top 300 Beer reviewers in this dataset, because they all have multiple beer reviews, which enables us to calculate user similarity. We consequently build a list of the top reviewers.
user = dict(Counter([b['review/profileName'] for b in data]).most_common(300))
top_users = list(user.keys())
sort(top_users)[:10]
array(['ADZA', 'ATLbeerDog', 'ATPete', 'AgentZero', 'AltBock',
'Arbitrator', 'AwYeh', 'BEERchitect', 'Beaver13', 'Beejay'],
dtype='|S16')
Now we construct a dictionary of the top reviewers and all the beers they have reviewed as well as a list of the beers in this dictionary.
from collections import defaultdict
beer_reviews = [[b['review/profileName'],b['beer/name']] for b in data if b['review/profileName'] in top_users]
top_beer_reviewers = defaultdict(list)
for k, v in beer_reviews:
top_beer_reviewers[k].append(v)
top_beer_reviewers = dict(top_beer_reviewers)
beers = top_beer_reviewers.values()
Next we construct a list of all unique beers. After we have done this we construct a matrix for all beer reviewers and whether they have reviewed a beer from our unique beer list. We have 446 unique beers in our list. Therefore each beer reviewer has a vector of 446 values long, 1 if the reviewer has reviewed the beer in our list, 0 if they have not.
unique_beers = set([b['beer/name'] for b in data])
def beerVector(beers):
return[1 if beer in beers else 0 for beer in unique_beers]
beer_matrix = map(beerVector, beers)
Next we use singular value decomposition to reduce the dimensionality of our beer reviewer matrix, which will make our similarity calculations faster. We use Scikit-Learn's truncated SVD.
import sklearn
from sklearn.decomposition import TruncatedSVD
SVD = TruncatedSVD(2, algorithm = 'arpack')
beerSVD = SVD.fit_transform(beer_matrix)
beerSVD = Normalizer(copy=False).fit_transform(beerSVD)
beerSVD[:10]
array([[ 0.77769132, 0.62864633],
[ 0.94543045, -0.32582397],
[ 0.91212858, 0.40990419],
[ 0.9582704 , -0.28586333],
[ 0.96164612, 0.27429315],
[ 0.91552468, -0.40226181],
[ 0.38365222, 0.92347765],
[ 0.89761428, -0.44078181],
[ 0.99846157, 0.05544803],
[ 0.9688946 , -0.24747375]])
I use Pandas dataframe to visualize the matrix, for me it is easier to see it in a dataframe
import pandas as pd
df=pd.DataFrame(beer_matrix,index=top_beer_reviewers.keys(),columns=unique_beers)
df.head(10)
Now we calcuate user similarities.
import numpy
similarity = np.asarray(numpy.asmatrix(beerSVD) * numpy.asmatrix(beerSVD).T)
df2 = pd.DataFrame(similarity,index=top_beer_reviewers.keys(), columns=top_beer_reviewers.keys())
df2.head()
FInally we build a function to give most similar users for a specific user.
similarity_matrix = df2.to_dict('records')
userLabels = dict(enumerate(top_beer_reviewers.keys()))
userLabels
{0: 'seanyfo',
1: 'billshmeinke',
2: 'womencantsail',
3: 'bluejacket74',
4: 'corby112',
5: 'UCLABrewN84',
6: 'flagmantho',
7: 'asabreed',
8: 'Dogbrick',
9: 'Gavage',
10: 'Deuane'...
def mostSimilarUsers(user):
u = userLabels.keys()[userLabels.values().index(user)]
return user, dict((k, v) for k, v in similarity_matrix[u].items() if v >= 0.9 and v < 1.0)
I have set the threshold for user similarity to 0.9 and less than 1.0. Scores of 1.0 usually represents the user themselves. Now when we call the function for a specific user we should get back all other users who have similarity scores above 0.9
mostSimilarUsers('seanyfo')
('seanyfo',
{'BeerAdvocate': 0.99678054247314196,
'BeerBelcher': 0.9601621967703986,
'BeerSox': 0.94818627301113112,
'BeerZack': 0.99419134620224725,
'Beerandraiderfan': 0.99225166535134779,
'BlackHaddock': 0.95958969582154008,
'Brent': 0.90651725530301841,
'CHILLINDYLAN': 0.999999796468103,
'Chelsea1905': 0.97592231870177604,
'ClockworkOrange': 0.91656788751028562,
'CrellMoset': 0.98597028945253073,
'Deuane': 0.98409474184894485,
'FosterJM': 0.94090020679906938,
'GbVDave': 0.9649820596064792,
'Halcyondays': 0.93604168404844224,
'HopDerek': 0.98898812968507122,
'JDV': 0.94312411404323704,
'JayQue': 0.9909058343918401,
'JeffTibbetts': 0.99736207867697646,
'JoeyBeerBelly': 0.96154965627973044,
'JohnGalt1': 0.97745310089077742,
'JohnQVegas': 0.96529614485641679,
'Monkeyknife': 0.99181951492472142,
'NJpadreFan': 0.99736122143528227,
'NeroFiddled': 0.94854849821114295,
'OWSLEY069': 0.96518059524808719,
'Offa': 0.91690376380652128,
'Phelps': 0.9972460199549017,
'Proteus93': 0.99414528327024709,
'RBorsato': 0.97827002559538423,
'Redrover': 0.94276524253050753,
'Reidrover': 0.93711249293736021,
'RoyalT': 0.99528124705020649,
'RuudJH': 0.98474900385992015,
'Seanibus': 0.99772436122025188,
'Slatetank': 0.98841615447140652,
'SpdKilz': 0.93806477587941062,
'Spikester': 0.90796469080751996,
'SurlyDuff': 0.92272710962799065,
'TKempe': 0.99884589287765524,
'TheGordianKnot': 0.99904226845886046,
'TheManiacalOne': 0.97134450626071367,
'Tilley4': 0.9999810862088554,
'Tone': 0.93770764527480399,
'UncleJimbo': 0.9899124089396788,
'Vancer': 0.9297833698929846,
'Wasatch': 0.91362264192868547,
'WesWes': 0.93300506261300042,
'Wetpaperbag': 0.90874557699858571,
'akorsak': 0.9649820596064792,
'akronzipfan': 0.92622485866257775,
'aracauna': 0.91280814013319056,
'barleywinefiend': 0.9997086436178384,
'beagle75': 0.99711534918742917,
'beerguy101': 0.98582217212272871,
'beerman207': 0.99288177573496561,
'beertunes': 0.937424107955107,
'blackie': 0.9959783129283486,
'brewerburgundy': 0.98698239667093657,
'callmescraps': 0.91755854674246962,
'ccrida': 0.98491965421524985,
'cjgator3': 0.94186471649897741,
'cnally': 0.97850709432051097,
'corby112': 0.92029722401877168,
'dirtylou': 0.90170011004960493,
'dyan': 0.98480121841647539,
'elgiacomo': 0.99520110401401352,
'emmasdad': 0.95525227083843445,
'flexabull': 0.96021981268384859,
'gabeerfan': 0.95585237516875543,
'genog': 0.97134450626071378,
'gford217': 0.92464173532714145,
'harpo111': 0.94608235979898347,
'harrymel': 0.9709612517327848,
'hopdog': 0.98735426058427345,
'jwc215': 0.96526294005864188,
'ktrillionaire': 0.98759669335935163,
'lackenhauser': 0.90228140819476721,
'maximum12': 0.96308705600935007,
'mdagnew': 0.99638372777533868,
'mduncan': 0.9585922259774714,
'mikereaser': 0.99888322046275535,
'msubulldog25': 0.98620192214539015,
'mynie': 0.99093632178552227,
'oberon': 0.97390807595406759,
'onix1agr': 0.94402182863157624,
'philbe311': 0.99684146203914281,
'rootbeerman': 0.99842874841652507,
'rvdoorn': 0.99095642358143576,
'schoolcb': 0.98901708128300903,
'socon67': 0.95349349362698488,
'tdm168': 0.92911314309421067,
'tempest': 0.99957877503799142,
'thagr81us': 0.98150899030601213,
'thierrynantes': 0.9809246609047616,
'wcudwight': 0.93488105133160393,
'wl0307': 0.99519578164811451,
'womencantsail': 0.96703924893934545,
'woodychandler': 0.98981049732546778,
'youradhere': 0.93449852805121825,
'zeff80': 0.96507067965241666,
'zerk': 0.94575593055506613,
'zoso1967': 0.99977596718328143})