Topic Modeling
Using Latent Dirichlet Allocation to assign categories to Amazon Fine Food Reviews. Data citation: Image-based recommendations on styles and substitutes J. McAuley, C. Targett, J. Shi, A. van den Hengel SIGIR, 2015
First we load, parse, and clean the data. I have only take 100 entries because the LDA Python algorithm is relatively slow and topic names eventually are applied manually
data=list(parse('/users/davidt/documents/cse_190/datasets2/finefoods.txt.gz')) [:100]
data[0]
{'product/productId': 'B001E4KFG0',
'review/helpfulness': '1/1',
'review/profileName': 'delmartian',
'review/score': '5.0',
'review/summary': 'Good Quality Dog Food',
'review/text': 'I have bought several of the Vitality canned dog food products and have found them all to be of good quality. The product looks more like a stew than a processed meat and it smells better. My Labrador is finicky and she appreciates this product better than most.',
'review/time': '1303862400',
'review/userId': 'A3SGXH7AUHU8GW'}
documents = [b['review/text'] for b in data]
from nltk.corpus import stopwords
import string
StopWords = stopwords.words('english')
def removeNonAscii(datum):
return "".join(i for i in s if ord(i)<128)
def removeStopWords(datum):
return [word for word in datum if word not in StopWords]
def tokenize(message):
import re
message = message.lower()
all_words = re.findall("[a-z0-9']+", message)
return set(all_words)
documents = [removeNonAscii(b) for b in documents]
documents = [tokenize(b) for b in documents]
documents = [removeStopwords(b) for b in documents]
documents[0]
['labrador',
'product',
'looks',
'quality',
'smells',
'better',
'several',
'good',
'food',
'appreciates',
'vitality',
'stew',
'finicky',
'meat',
'canned',
'like',
'dog',
'products',
'processed',
'found',
'bought']
I have decided on 10 topics, K = 10. Gibbs Sampling is used to extract the aforementioned distributions. Where we only know some of the conditional distributions, Gibbs Sampling takes some initial values of parameters and iteratively replaces those values conditioned on its neighbors. Every word in all the text reviews is assigned a topic at random, iterating through each word, weights are constructed for each topic that depend on the current distribution of words and topics in the document, and we iterate through this entire process. I have listed only the ten most common words per topic.
for k, word_counts in enumerate(topic_counts):
for word, count in word_counts.most_common()[:10]:
if count > 0: print k, word, count
For example topic 0 looks like this:
- 0 oatmeal 14
- 0 good 12
- 0 cinnamon 10
- 0 like 10
- 0 instant 10
- 0 mccann's 10
- 0 brand 9
- 0 regular 8
- 0 sugar 8
- 0 variety 8
Total observations in the dataset: 568,454. The dataset was split into training and test datasets, random 50-50 split. In order to utilize Latent Dirichlet Allocation for topic modeling feature vectors needed to be created from the text reviews. All the reviews were converted to a bag of words and stop words removed. Quantitatively evaluating the model is done through a ‘perplexity’ score, which measures the log-likelihood of the held-out test set.Lower perplexities are better. However model-fit in regards to topic-modeling does not seem to be an intuitive way to measure whether the topics chosen are ‘accurate’ from a human perspective. Indeed in ‘Reading Teat Leaves: How Humans Interpret Topic Models,’ Sean Gerrish, Chong Wang, and David Blei find that traditional metrics do not capture whether topics are coherent, human measures of interpretability are negatively correlated with traditional metrics to measure the fit of topic models. This assumption will be tested when labels are assigned to the topics created with model. The perplexity metric is used to choose the final model that will be interpreted.
| Topics | Perplexity |
|---|---|
| 10 | 2439.96 |
| 15 | 2459.95 |
| 20 | 2478 |
| 25 | 2487 |
| 30 | 2434.61 |
| 50 | 2573.42 |
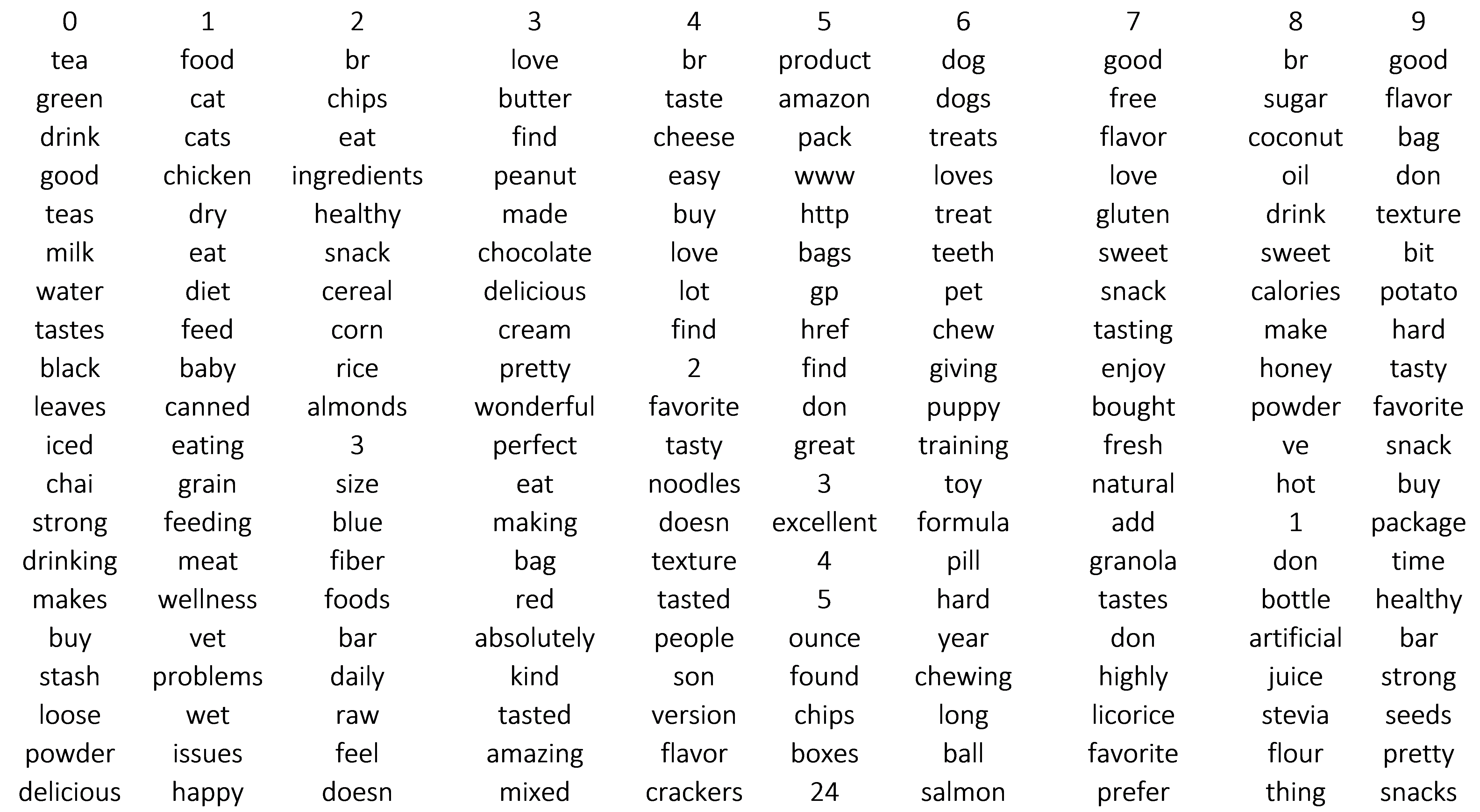
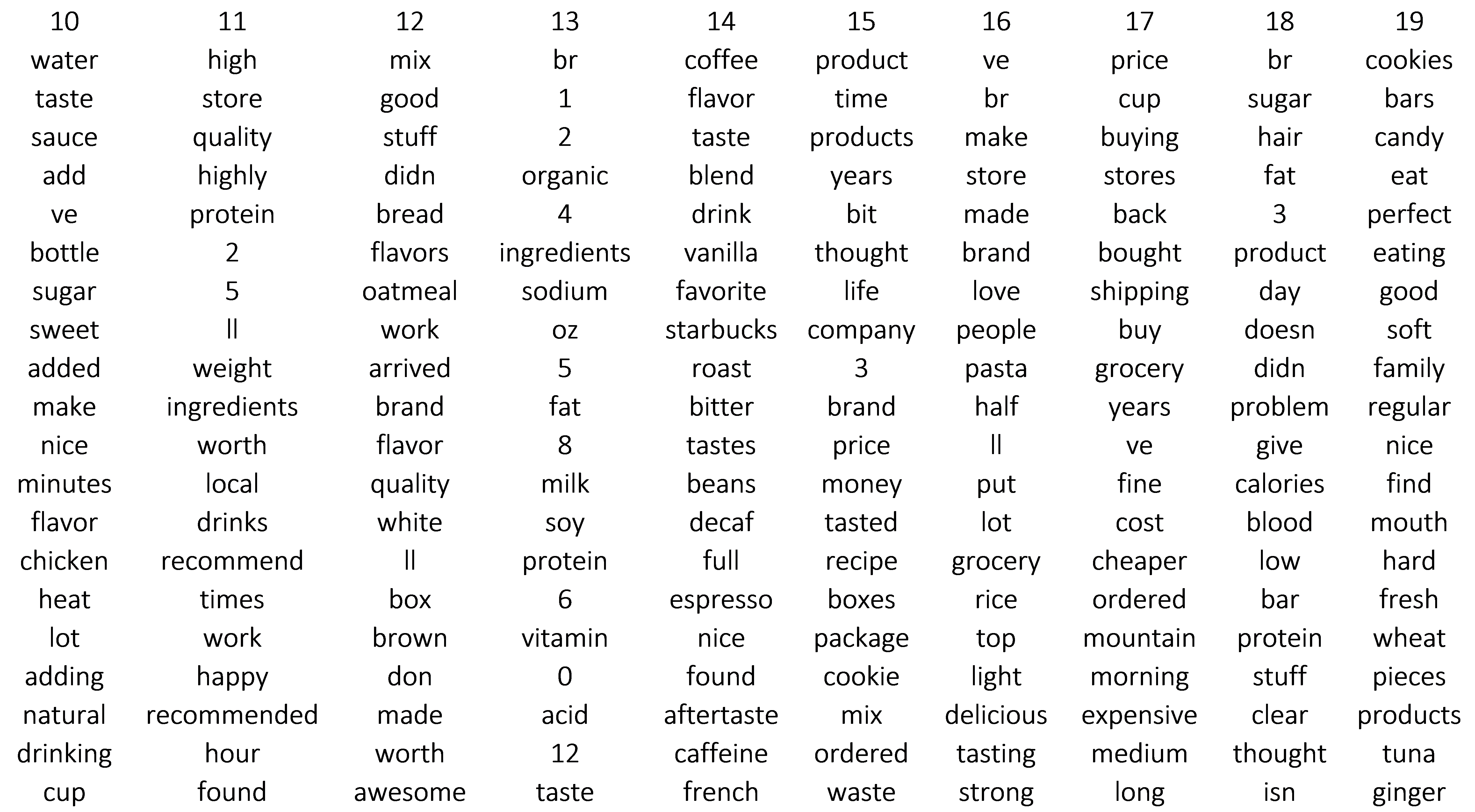
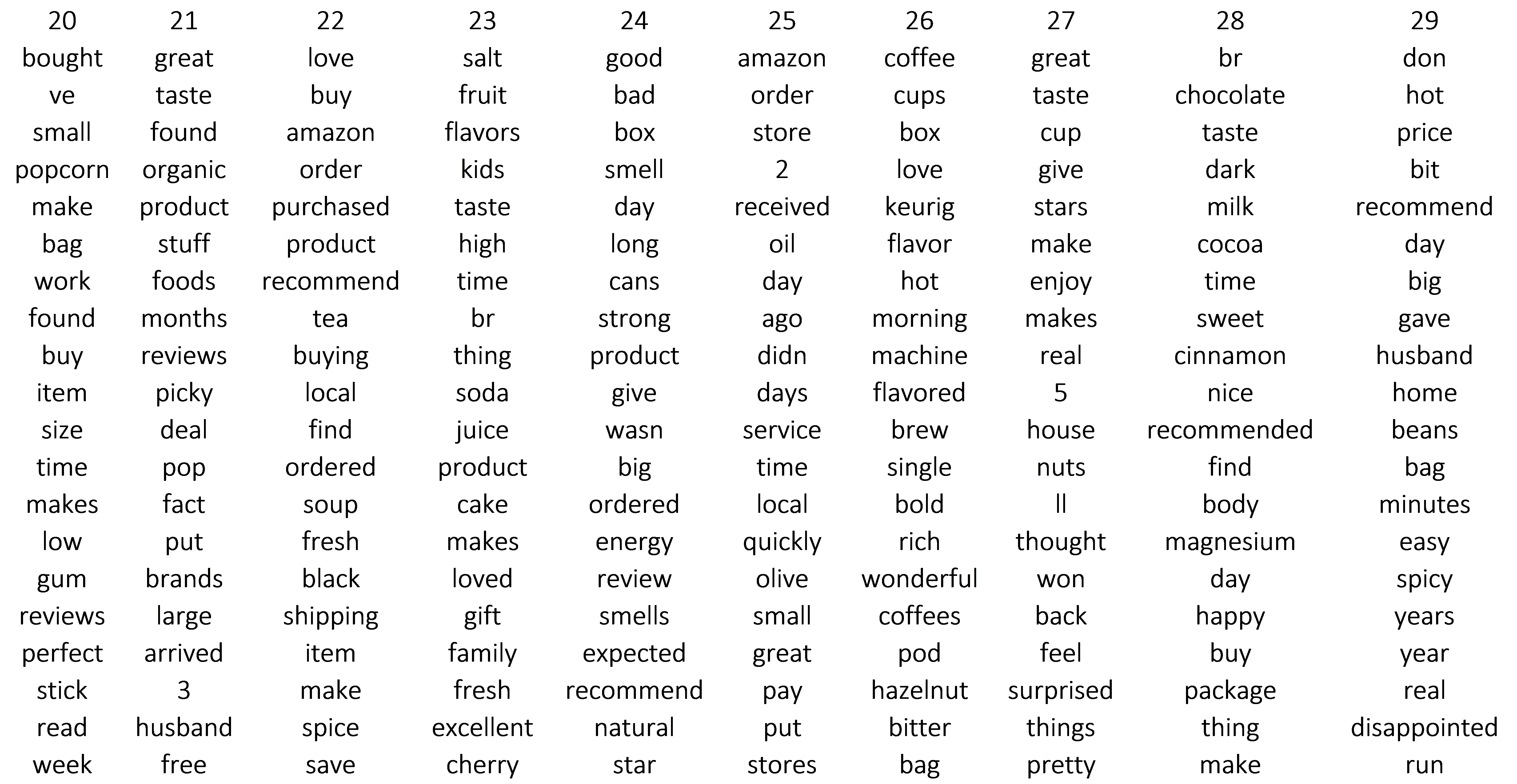
Some of these are easy to categorize, topic 6 looks pet related, topic 19, candy. Some are vague, topic 29 which contains words such as: “husband, beans, easy, spicy, and disappointed.” Manually labeling these topics seems fraught with difficulty. However to test the predictions of the model several categories relatively easy topics are labeled.
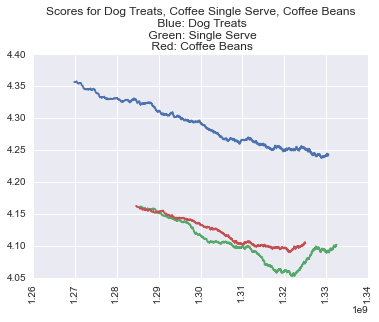
- Topic 6: Dog Treats
- Topic: 14 Coffee
- Topic 26: Coffee Condiments The model was used to predict topics for the test dataset. Topic frequency is plotted below.
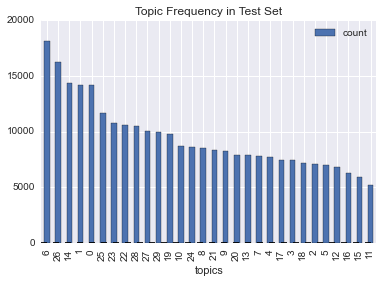
Now that categories are assigned we can track user behavior over time.