6/20/2015: Simple Polarity Scores with the New York Times API and TextBlob
Quick and Dirty Method to Search for all Relevant New York Times Article Comments and Classify Text. First I want to filter comments to only those articles that were the most popular articles for that week.
def emailed_results(data):
for i, document in enumerate(data):
return data['results']
def parsed_mailed(data):
mailed = []
for b in data:
dic = {}
dic['sub-title'] = b['abstract']
dic['byline'] = b['byline']
dic['column'] = b['column']
dic['type'] = b['des_facet']
dic['date'] =b['published_date']
dic['section'] = b['section']
dic['title'] = b['title']
dic['url'] = b['url']
mailed.append(dic)
return mailed
def title(data):
for i, title in enumerate(d['title'] for d in data):
print i,title
def url(data):
for i, url in enumerate(d['url'] for d in data):
print i,url
def most_mailed(days, api):
import urllib
import json
bucket = 'http://api.nytimes.com/svc/mostpopular/v2/mostemailed/all-sections/'
string = bucket+days+api
response_string = urllib.urlopen(string).read()
response_dictionary = json.loads(response_string)
results = emailed_results(response_dictionary)
parsed_results = parsed_mailed(results)
titles = title(parsed_results)
urls = url(parsed_results)
return titles, urls
#past seven days
days='7?'
api='api-key=##########'
#call the function
most_mailed(days, api)
| Title | url |
|---|---|
| To Lose Weight, Eating Less Is Far More Important Than Exercising More | |
| How to Pick a Cellphone Plan for Traveling Abroad | |
| Naomi Oreskes, a Lightning Rod in a Changing Climate | |
| How to Make Online Dating Work | |
| America’s Seniors Find Middle-Class ‘Sweet Spot’ | |
| Experts on Aging, Dying as They Lived | |
| What It’s Like as a ‘Girl’ in the Lab | |
| Three Simple Rules for Eating Seafood | |
| Pope Francis, in Sweeping Encyclical, Calls for Swift Action on Climate Change | |
| Stop Revering Magna Carta | |
| Review: Pixar’s ‘Inside Out’ Finds the Joy in Sadness, and Vice Versa | |
| Cardinals Investigated for Hacking Into Astros’ Database | |
| In Tucson, an Unsung Architectural Oasis | |
| Magna Carta, Still Posing a Challenge at 800 | |
| Democrats Being Democrats | |
| Black Like Who? Rachel Dolezal’s Harmful Masquerade | |
| A Sea Change in Treating Heart Attacks | |
| In ‘Game of Thrones’ Finale, a Breakdown in Storytelling | |
| My Choice for President? None of the Above | |
| The Family Dog |
Next we loop through the list of articles, and also get all the comments from each article. This takes several helper functions, the final function is called below.
df = []
for b in articles:
initial_df = nytimes(b)
df = df + initial_df
print 'Processing ' + str(b) + '...'
Processing http://www.nytimes.com/2015/06/16/upshot/to-lose-weight-eating-less-is-far-more-important-than-exercising-more.html...
Processing http://www.nytimes.com/2015/06/21/travel/how-to-pick-a-cellphone-plan-for-traveling-abroad.html...
Processing http://www.nytimes.com/2015/06/16/science/naomi-oreskes-a-lightning-rod-in-a-changing-climate.html...
Processing http://www.nytimes.com/2015/06/14/opinion/sunday/how-to-make-online-dating-work.html...
Processing http://www.nytimes.com/2015/06/15/business/economy/american-seniors-enjoy-the-middle-class-life.html...
Processing http://opinionator.blogs.nytimes.com/2015/06/19/depressed-try-therapy-without-the-therapist/...
Processing http://opinionator.blogs.nytimes.com/2015/06/17/experts-on-aging-dying-as-they-lived/...
Processing http://www.nytimes.com/2015/06/21/health/saving-heart-attack-victims-stat.html...
Processing http://www.nytimes.com/2015/06/18/opinion/what-its-like-as-a-girl-in-the-lab.html...
Processing http://www.nytimes.com/2015/06/19/world/europe/pope-francis-in-sweeping-encyclical-calls-for-swift-action-on-climate-change.html...
Processing http://www.nytimes.com/2015/06/14/opinion/three-simple-rules-for-eating-seafood.html...
Processing http://www.nytimes.com/2015/06/15/opinion/stop-revering-magna-carta.html...
Processing http://www.nytimes.com/2015/06/19/movies/review-pixars-inside-out-finds-the-joy-in-sadness-and-vice-versa.html...
Processing http://www.nytimes.com/2015/06/21/opinion/sunday/is-your-boss-mean.html...
Processing http://www.nytimes.com/2015/06/17/sports/baseball/st-louis-cardinals-hack-astros-fbi.html...
Processing http://www.nytimes.com/2015/06/14/travel/in-tucson-an-unsung-architectural-oasis.html...
Processing http://www.nytimes.com/2015/06/15/world/europe/magna-carta-still-posing-a-challenge-at-800.html...
Processing http://www.nytimes.com/2015/06/15/opinion/paul-krugman-democrats-being-democrats.html...
Processing http://www.nytimes.com/2015/06/16/opinion/rachel-dolezals-harmful-masquerade.html...
Processing http://www.nytimes.com/2015/06/16/arts/television/in-game-of-thrones-finale-a-breakdown-in-storytelling.html...
We have collected all the comments from all the most-emailed articles of the past seven days
len(df)df[0]
{'comment': u'The only way to lose weight permanently and arrive at a normal weight (117 pounds for me) is to create a calorie deficit and then a calorie equilibrium once that goal is achieved.
Thirty-five hundred calories eaten but not burned is equal to one pound of fat gained and 3,500 calories burned, but not consumed is equal to one pound of fat lost. Obviously eating 3,500 calories is a lot quicker than burning them. It would take 35 miles of walking to do that.
Fifteen years ago I was obese and about 70 pounds heavier, but I have maintained a normal weight since losing my excess weight in the year 2,000.
After studying the long-term research results, I started free weight loss groups of people who were suffering from my problem. We logged our daily calories, exercise and weight with each other. I still do it and you can join me if you are motivated and have less than 100 pounds to lose. You can see our results and my before and after pictures on www.permanentweightloss.org.
Let me know if this interests you by emailing me at russellk100@gmail.com. See you lighter soon?',
'comment_type': u'comment',
'date': u'1434435437',
'editorsSelection': 0,
'email': u'russellk100@gmail.com',
'location': u'New York City',
'login': None,
'name': u'Roberta Russell',
'recommend': 23,
'replies': [],
'update_date': u'1434435486'}
I am kind of curious about recommended comments and those comments selected by the editor
import numpy as np
np.mean([b['editorsSelection'] for b in df])np.mean([b['recommend'] for b in df])time=np.asarray([b['date'] for b in df]).astype(float)
recommendations=np.asarray([b['recommend'] for b in df]).astype(float)
import matplotlib.pyplot as plt
import seaborn
model = zip( time, recommendations)
model.sort()
sliding = []
windowSize = 100
tSum = sum([x[0] for x in model[:windowSize]])
rSum = sum([x[1] for x in model[:windowSize]])
for i in range(windowSize,len(model)-1):
tSum += model[i][0] - model[i-windowSize][0]
rSum += model[i][1] - model[i-windowSize][1]
sliding.append((tSum*1.0/windowSize,rSum*1.0/windowSize))
X = [x[0] for x in sliding]
Y = [x[1] for x in sliding]
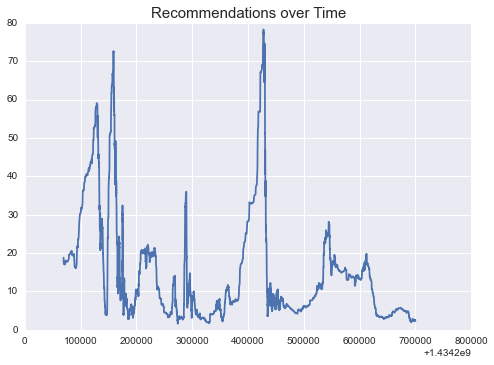
plt.plot(X, Y)
plt.title("Recommendations over Time", fontsize=15)
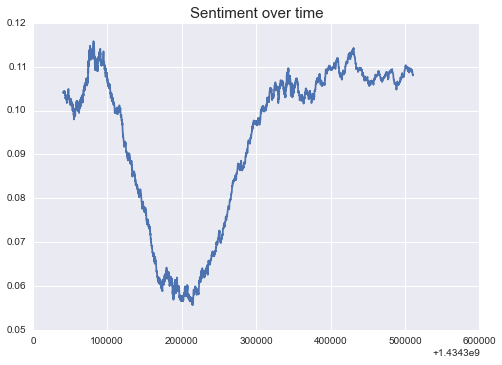
One of the quickest ways to get a read on text sentiment without having to build your own classifier is to use TextBlob
from textblob import TextBlob
text=[b['comment'] for b in df]
text=[word.strip("!\"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~").lower() for word in text]
blobs=[]
for b in text:
blobs.append(TextBlob(b).sentiment.polarity)
blobs[:10]
[0.03712121212121212,
0.048571428571428585,
0.2380952380952381,
0.08571428571428573,
0.09743589743589742,
-0.8,
0.09166666666666667,
0.25,
0.08240740740740739,
0.09757142857142857]